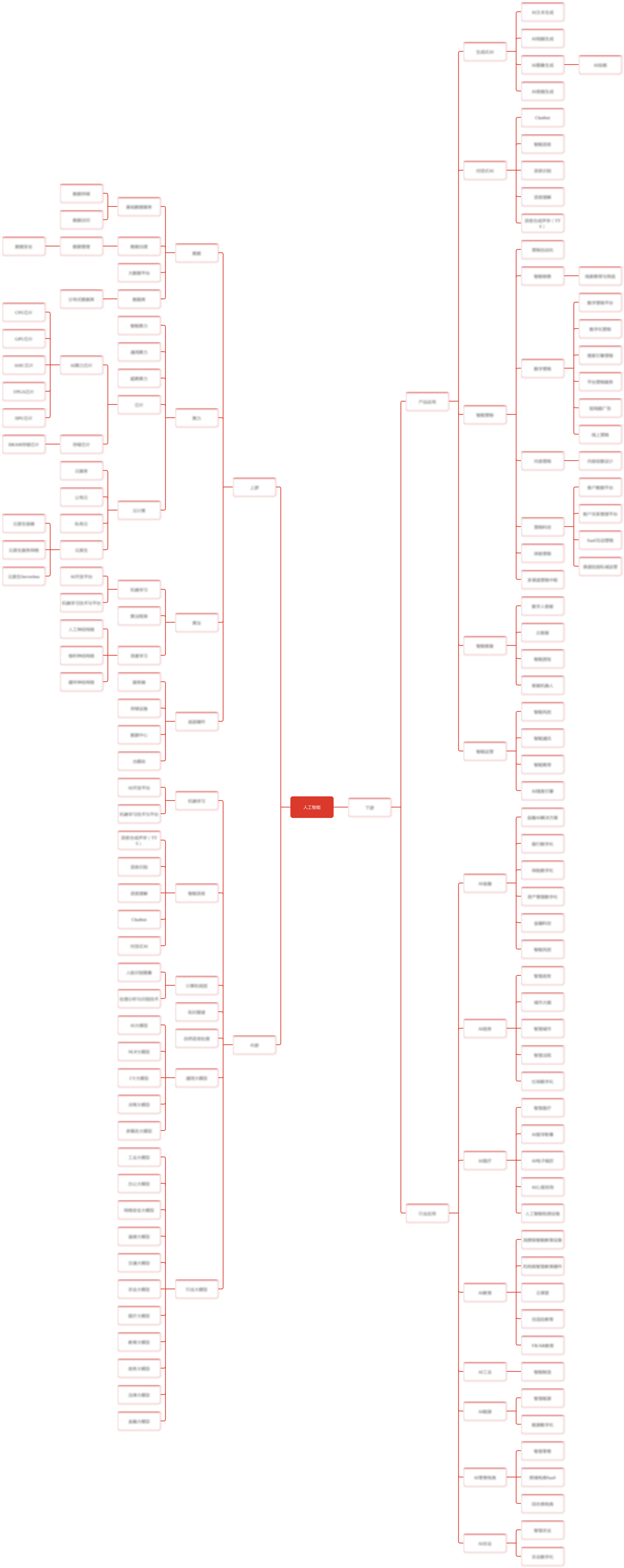
中国NLP大模型行业正处在雏形期,众多厂商各自分别投入推出自己的大模型。截止2023年5月,中国的语言大模型多达79个,但大部分的表现不尽如人意,与Chatgpt、LLama以及Claude等国际领先NLP大模型水平相差较远。当前市场上,中国NLP大模型虽与国际顶尖的NLP大模型还有一定的差距,但差距逐渐在缩小。当前中国NLP大模型的竞争格局如下:第一梯队:百度的文心一言以及科大讯飞的星火。这两个大模型在业界的认可度较高,在多项不同的独立测评中排名第一或第二,是中国NLP大模型行业的领导者。第二梯队:由清华大学研究技术成果转化的ChatGLM以及阿里云的通义千问。这两个大模型的认可度也较高,但在整体测评结果表现中较第一梯队有明显的逊色,其中ChatGLM模型参数量仅为62亿,相比百度的2,600亿以及通义千问的上万亿规模相差甚远,但由于其优质的调参水准和数据集,整体表现在前列。第三梯队:商汤的商量、名日之梦的Minimax、昆仑万维的天工、复旦大学的MOSS、华为的盘古NLP大模型以及腾讯的混元大模型。第三梯队的模型有一定的市场竞争力,综合认可度较高,但在各类测评的榜单中排名较低或出现情况较少。部分第三梯队的企业具备强大的研发能力与模型规模,具备向上梯队移动的潜力。


 问题核实后,平台会赠送头豹点表示感谢
问题核实后,平台会赠送头豹点表示感谢

 未经平台授权,禁止转载
未经平台授权,禁止转载



 产业链阅读权益
产业链阅读权益